NUMA-Aware操作系统对NUMA系统的支持分为两个层面:
- 操作系统本身完成大多数关于进程、内存、IO位置的决策,向用户程序隐藏NUMA拓扑信息的细节。这样做的好处操作系统可以进行全局的NUMA资源优化,同时用户程序可以透明的使用NUMA硬件资源而无需关心底层亲缘性细节。
- 操作系统同时提供一组用户接口(NUMA API),以供特殊需求的用户对NUMA内存分配、调度策略进行重载和显式的控制,以实现复杂应用的手动调优。
1. NUMA系统内存分配
Linux的NUMA系统的内存按照Node划分,一个NUMA Node对应一个Memory Node。一个Memory Node下根据不同的用途划分为不同的Zones(如ZONE_DMA、ZONE_NORMAL等)。
1.1 内存分配策略
NUMA系统下从哪里分配内存是由Memory Policies决定的。内存分配策略可以针对全系统级别的(System Default Policy),也可以针对某一进程(Task/Process Policy),还可以针对进程中的某一段区域(VMA Policy)。如果考虑到动态共享库问题,还包括共享级策略(Shared Policy)。就优先级而言,进程级的策略高于系统默认策略,而内存区域的策略又可以重载进程级的策略。系统的默认Policy是由系统进程级的内存分配策略可以通过fork进行继承。系统提供get/set_mempolicy和mbind系统调用,以供
内核支持的内存分配策略有三种:
- MPOL_BIND:绑定策略,只能从特定的一组Nodes上分配内存。
- MPOL_PREFERED:即优先从指定的Node上分配,如果不能满足就再从其他Node上分配。如果指定的Node就是执行内存分配的CPU所在的Node,就称之为Local Allocation。
- MPOL_INTERLEAVE:交替策略,它指定在指定的几个节点上,以页为单位,交叉分配内存(round-robin)。
系统的默认分配策略是本地分配(即Local Allocation),但是在启动过程中使用交替策略,这样内核的数据结构是分布在所有Node上的,从而避免启动核所在Node负载过重。一旦系统第一个进程(init)开始执行,策略就变成了本地分配。
1.2 first touch原则
设置内存分配策略并不触发任何实际的分配动作,没有访问过的虚拟空间或者ZERO Page事实上都没有对应实际的物理页面。因此,只有在第一次访问出发缺页时,这些内存分配策略才会其作用,称为First Touch原则。
一个进程可以设置自己的Memory Policy,但是如果多个进程共用同一物理页(如共享库情况),那么Memory Policy就有可能失效。因为内存页的第一个使用者将决定这个页的分配策略。
1.3 页面迁移
如果任务频繁使用的页面是在远程Node,就有必要将其迁移到本地Node。Linux提供给用户页面迁移的接口(migrate_pages/move_pages系统调用),其中migrate_pages可以把一个进程的所有页面迁移到制定Node,move_pages则是可以把一组页面迁移。普通权限用户只能迁移那些只被本进程引用的页面。要迁移所有页面需要ROOT权限。
但是很难保证将任务所有页面都迁移到本地节点,因为有些代码段是被大量的共享使用的,特别是考虑到动态链接库的情况下。
2. NUMA API
2.1 NUMA工具
numactl是设定进程NUMA策略的命令行工具。对于那些无法修改和重新编译的程序,它可以进行非常有效的策略设定。numactl使管理员可以通过简单的命令行调用来设定进程的策略, 并可以集成到管理脚本中。
numactl的主要功能包括:
- 设定进程的内存分配基本策略
- 限定内存分配范围,如某一特定节点或部分节点集合
- 对进程进行节点或节点集合的绑定
- 修改命名共享内存,tmpfs或hugetblfs等的内存策略
- 获取当前策略信息及状态
- 获取NUMA硬件拓扑
下面是使用numactl设定进程策略的实例:
numactl --cpubind=0 --membind=0,1 program
其意义为:在节点0上的CPU运行名为program的程序,并且只在节点0,1上分配内存。Cpubind的参数是节点编号,而不是cpu编号。在每个节点上有多个CPU的系统上,编号的定义顺序可能会不同。
下面是使用numactl更改共享内存段的分配策略的实例:
numactl --length=1G --file=/dev/shm/interleaved --interleave=all
其意义为: 对命名共享内存interleaved进行设置,其策略为全节点交织分配,大小为1G。
numastat是获取NUMA内存访问统计信息的命令行工具。对于系统中的每个节点,内核维护了一些有关NUMA分配状态的统计数据。numastat命令会基于节点对内存的申请,分配,转移,失败等等做出统计,也会报告NUMA策略的执行状况。这些信息对于测试NUMA策略的有效性是非常有用的。
2.2 LIBNUMA
尽管numactl能够用作进程级别的内存控制,但其缺点也很明显:分配策略作用于整个进程,无法指定到线程或者特定内存区域。Libnuma为更加精细的控制提供了API接口。
Libnuma库的函数包括以下几组:
- 环境信息 – 包括一组用于获取系统内存和CPU拓扑信息的函数,如系统节点数目,特定节点的内存大小等等。
- 进程策略 – 包括一组用于获取,设定和更改进程级策略的函数;
- 内存区域策略 – 包括一组用于设定特定内存区域策略的函数;
- 节点绑定 - 将线程绑定到指定节点或节点组的函数;
- 分配函数 - 忽略当前进程策略,直接使用特定的策略进行分配的一组函数;
- 其他辅助函数
详细API可参考numa(3) manpage。
3. NUMA系统调度
3.1 调度域
Linux操作系统从2.6.7-rc1版本引入调度域概念。调度域是NUMA硬件拓扑在任务调度器里的抽象,调度器有了硬件层级拓扑信息,就可以更好的进行负载平衡,同时可以根据不同层级细化调度策略。
简单来说,调度域仿照硬件拓扑结构把CPU进行分组。每个调度域其实就是具有相同属性的一组 cpu 的集合。并且跟据 SMT, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别。不同级之间通过指针链接在一起,从而形成一种的树状的关系。每个调度域的CPU集合具有具有相同的调度策略。
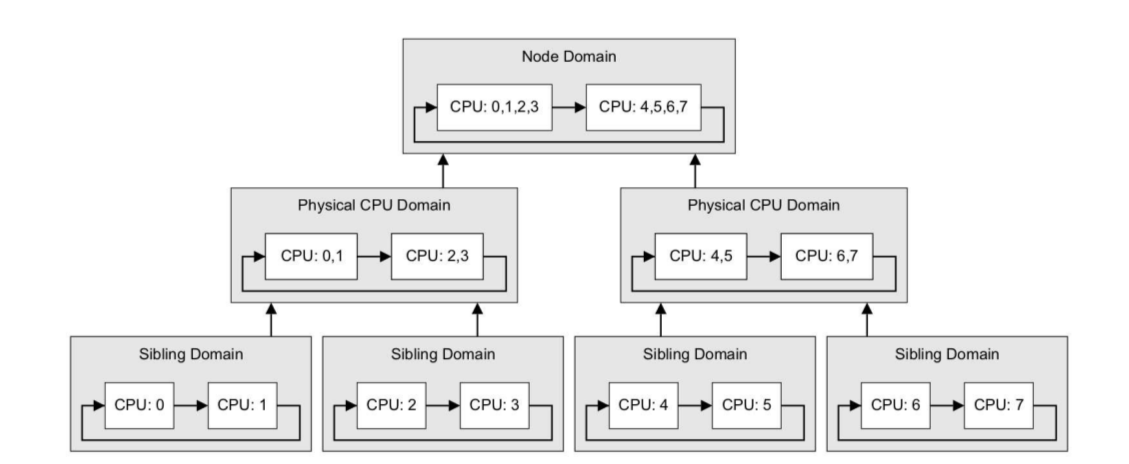
层级越低的调度域内的CPU共享的资源越多,因此大多数负载平衡到要在最底层的调度域进行,以减少任务迁移带来的性能开销。
系统的负载平衡可以按照触发的类型分为事件平衡(event balancing)和主动平衡(active balancing)。其中时间平衡时候特定事件触发的,如任务状态的变化(如CPU进入IDLE状态) 或特殊的系统调用(fork/clone/exec) ,而主动平衡是指系统按照一定的时间间隔进行动态的负载平衡。对于这两类的负载平衡,调度域有不同的。
事件平衡
对于事件触发类平衡,系统定义了若干属性,用来确定一个调度域的调度策略:
#define SD_LOAD_BALANCE 0x0001 /* Do load balancing on this domain. */
#define SD_BALANCE_NEWIDLE 0x0002 /* Balance when about to become idle */
#define SD_BALANCE_EXEC 0x0004 /* Balance on exec */
#define SD_BALANCE_FORK 0x0008 /* Balance on fork, clone */
#define SD_BALANCE_WAKE 0x0010 /* Balance on wakeup */
#define SD_WAKE_AFFINE 0x0020 /* Wake task to waking CPU */
#define SD_SHARE_CPUCAPACITY 0x0080 /* Domain members share cpu power */
#define SD_SHARE_POWERDOMAIN 0x0100 /* Domain members share power domain */
#define SD_SHARE_PKG_RESOURCES 0x0200 /* Domain members share cpu pkg resources */
#define SD_SERIALIZE 0x0400 /* Only a single load balancing instance */
#define SD_ASYM_PACKING 0x0800 /* Place busy groups earlier in the domain */
#define SD_PREFER_SIBLING 0x1000 /* Prefer to place tasks in a sibling domain */
#define SD_OVERLAP 0x2000 /* sched_domains of this level overlap */
#define SD_NUMA 0x4000 /* cross-node balancing */
如果一个逻辑 CPU 进入了 IDLE 状态,并且它所属的 domain 设置了 SD_BALANCE_NEWIDLE,则马上就会进行 balance,把忙的 CPU 上的进程 move 过来,从而最大的发挥多 CPU 的优势。而SD_BALANCE_WAKE是指,如果一个进程wakeup时候可以在该域内进行迁移。一般在最低层级的Domain上就会设置SD_BALANCE_NEWIDLE和SD_BALANCE_WAKE,因为在SMT级别,逻辑CPU基本上是共享所有的资源的(主要是各级Cache),因此平衡带来的开销极小。
当一个进行调用 exec() 执行时,本来就是要加载一个新进程,缓存本来就会失效,所以原则上可以迁移到任何节点上。调度器就会找设置了 SD_BALANCE_EXEC 标记的最高层级 domain 。然后把进程移动到那个 domain 中最闲的 CPU 上。SD_BALANCE_FORK与SD_BALANCE_EXEC的情况类似。
主动平衡
每次时钟中断到来,如果发现当前 cpu 的运行队列需要进行下一次的 balance 的时间已经到了,则触发 SCHED_SOFTIRQ 软中断。根据 domain 的级别,从下往上扫描每一级 Scheduling Domain 。如果发现这个 domain 的 balance 之间的间隔时间到了,则进一步进行 task 的迁移。不同级别的 domain 是会有不同的间隔时间的。而且级别越高值越大,因为移动 task 的代价越大。
SMT调度
当任务数少于逻辑CPU数时,调度器会尽量让任务独享一个物理核而不是让同一物理核的两个线程都处于busy状态。当系统要在逻辑CPU(即物理线程上)上要运行一个高优先级的任务时,调度器会让同一物理CORE上的另一物理线程进入IDLE状态空闲一会儿。
3.2 Numa调度
在3.8版本之前,Linux的调度器都对进程的页面位置一无所知,所有调度的决策紧紧是依赖进程对应的Cache热度。如果调度器仅仅是将进程的执行迁移到另一个Node,而使用的页面仍然留在原Node,那么跨节点的访存开销将会大大增加。一旦出现这种情况,想要取得最佳性能的用户就会避免内核调度器的干扰,利用taskset/cpuset等机制将程序绑定在特定的Node内。
3.8版本开始,Linux在调度器增加了一个框架,使得调度器可以考虑综合页面的Node位置信息,然后在合适的情况下自动迁移页面。
3.13版本内核增加了大量的策略,以尝试尽量把进程放到离它的所使用内存近的地方,同时综合考虑共享页面及透明大页的情况。
4. NUMA IO调优
NUMA下的IO性能调优与非调优差别巨大。

NUMA 下IO调优的整体原则是让设备驱动(内核线程)、中断、DMA区域尽量落在设备对应的Node内。
-
PCIe设备与Node的亲缘性通过以下接口确定:
#dmidecode -t slot#cat /sys/devices/pci0000:50/0000:50:09.0/numa_node这个信息一般情况下是从ACPI表里获取的,如果获取值为-1,标识系统不清楚PCIe设备的Locality,通过更新升级BIOS可以解决。
确定好位置关系后,对于HBA类的发起方,应尽可能能采用离PCIe最近的Node Core进行IO事务发起。
-
利用设备IRQ的亲缘性设置接口进行中断绑定:
#echo [CPU mask] > /proc/irq/[num]/smp_affinity -
利用taskset把驱动中的内核线程绑定到Node内CPU List:
#taskset -p -c [cpumask] [pid]